
骨格推定というものを触るかもしれないので、サクッとどんなもんか調べて触ってみました。
骨格推定とは
- 画像や動画から人物の骨格を推定する技術
- 推定処理はAI
- 骨格検知、骨格検出、骨格認識 等言い回しはいくつかある
今回はWebカメラで写った動画を元に、骨格推定を行うというサンプルを作りました。
参考にした記事はこちら
※ 古めの記事なのでgithubのコード等は無くなってました
使用ライブラリ
- TensorFlow.js
- PoseNet
PoseNetはTensorFlow.jsを使用した、ブラウザで実行可能な姿勢推定ディープラーニングモデルです。
処理の流れ
処理の大枠の流れは以下です
- htmlのvideoタグと使ってブラウザとwebカメラを接続する
videoの動画をcanvasに描画する← すみませんこちらは勘違いでした。正しくはvideoの上にcanvasを重ねる、でした。- canvasに描画される度に骨格推定処理を走らせる
- 骨格推定処理から取得した骨格座標をcanvasに描画する
今回はPoseNetのうち、単一姿勢を検出するメソッド estimateSinglePose を使用しました。
estimateSinglePose の戻り値に keypoints という配列があります。
この中に各部位ごとの座標(右手首がどの画像の位置にあるか?等の座標情報)が入っているので、こちらを描画に使用します。
得られる部位が全部で17箇所あります。
今回はわかりやすく左右の手首の座標を表示してみました。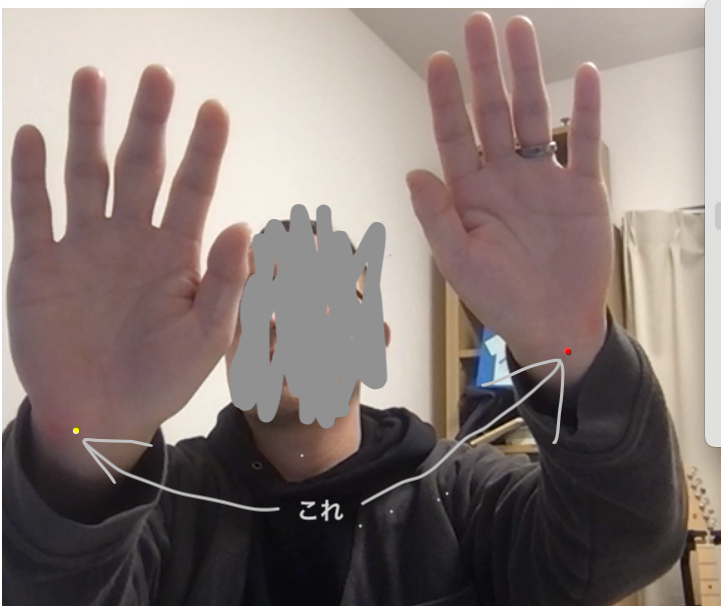
所感
良さそう
- 特に準備するものもなく、PCとWebカメラだけでサクッと実装できた
- ライブラリhtmlから読み込んだのは2つのみ
- 骨格推定処理の細かいとこがわからなくても、インターフェースがわかりやすい
懸念点
- 実際に実装する場合、動かす端末のスペック要件がわかってない(動かす環境は非力なマシンになる想定なので)
- 上記懸念があるので、端末ローカルで稼働させるのではなくAPIのような形で外部で処理させたいが方法がわかってない
という感じでした。
PoseNet自体はかなり前に公開されているし、参考にした記事も2018年のものなので「なにを今更」的な感じになっているかもしれないが、まあやってみた系の記事として残しておきます。
コード
html
<!DOCTYPE html>
<html>
<head>
<script src="https://unpkg.com/@tensorflow/tfjs"></script>
<script src="https://unpkg.com/@tensorflow-models/posenet"></script>
</head>
<body>
<video
id="video"
width="800px"
height="600px"
autoplay="1"
style="position: absolute"
></video>
<canvas
id="canvas"
width="800px"
height="600px"
style="position: absolute"
></canvas>
<div class="ball"></div>
</body>
<script src="https://cdnjs.cloudflare.com/ajax/libs/stats.js/r16/Stats.js"></script>
<script src="./posenet_sample.js"></script>
</html>js
const imageScaleFactor = 0.2;
const outputStride = 16;
const flipHorizontal = false;
const stats = new Stats();
const contentWidth = 800;
const contentHeight = 600;
bindPage();
async function bindPage() {
const net = await posenet.load(); // posenetの呼び出し
let video;
try {
video = await loadVideo(); // video属性をロード
} catch (e) {
console.error(e);
return;
}
detectPoseInRealTime(video, net);
}
// video属性のロード
async function loadVideo() {
const video = await setupCamera(); // カメラのセットアップ
video.play();
return video;
}
// カメラのセットアップ
// video属性からストリームを取得する
async function setupCamera() {
const video = document.getElementById("video");
if (navigator.mediaDevices && navigator.mediaDevices.getUserMedia) {
const stream = await navigator.mediaDevices.getUserMedia({
audio: false,
video: true,
});
video.srcObject = stream;
return new Promise((resolve) => {
video.onloadedmetadata = () => {
resolve(video);
};
});
} else {
const errorMessage =
"This browser does not support video capture, or this device does not have a camera";
alert(errorMessage);
return Promise.reject(errorMessage);
}
}
// 取得したストリームをestimateSinglePose()に渡して姿勢予測を実行
// requestAnimationFrameによってフレームを再描画し続ける
function detectPoseInRealTime(video, net) {
const canvas = document.getElementById("canvas");
const ctx = canvas.getContext("2d");
const flipHorizontal = true; // since images are being fed from a webcam
async function poseDetectionFrame() {
stats.begin();
let poses = [];
const pose = await net.estimateSinglePose(
video,
imageScaleFactor,
flipHorizontal,
outputStride
);
poses.push(pose);
ctx.clearRect(0, 0, contentWidth, contentHeight);
ctx.save();
ctx.scale(-1, 1);
ctx.translate(contentWidth, 0);
ctx.drawImage(video, 0, 0, contentWidth, contentHeight);
ctx.restore();
poses.forEach(({ score, keypoints }) => {
// TODO: 取得した骨格にポイントを描画したい場合
// keypoints.map((kp, index) => {
// drawWristPoint(kp, ctx);
// });
// とりあえず左右の手首のみ描画してみた ポイントの色もとりあえず左右の違いが判別できるように
drawWristPoint(keypoints[9], ctx, "red");
drawWristPoint(keypoints[10], ctx, "yellow");
});
stats.end();
requestAnimationFrame(poseDetectionFrame);
}
poseDetectionFrame();
}
// 与えられたKeypointをcanvasに描画する
function drawWristPoint(wrist, ctx, color) {
ctx.beginPath();
ctx.arc(wrist.position.x, wrist.position.y, 3, 0, 2 * Math.PI);
ctx.fillStyle = color;
ctx.fill();
}